{kind=link}
モデリング変換なし
OpenGLアプリケーションのみを利用
シェーダを利用



/*
** メイン関数
*/
int main( int argc, char *argv[] )
{
... 省略 ...
/* GLSLの初期設定 */
// init_glsl();
... 省略 ...
/* GLSLの終了設定 */
// fin_glsl();
... 省略 ...
}
/*
** ウィンドウの描画
*/
static void display( void )
{
/* 画面のクリア */
glClear( GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT );
/* モデルビュー変換行列の初期化(単位行列にする) */
glLoadIdentity();
/* 視野変換(ビューイング変換)の設定 */
gluLookAt( 0.0, 0.0, 1.0, /* 視点位置 */
0.0, 0.0, 0.0, /* 注目位置 */
0.0, 1.0, 0.0 ); /* 上向きベクトル */
/* 4角形ポリゴンの描画 */
/* 4個の頂点にテクスチャ座標を割り当てる */
glBegin( GL_QUADS );
glTexCoord2d( 0.0, 0.0 );
glVertex3d( 0.0, 0.0, 0.0 );
glTexCoord2d( 1.0, 0.0 );
glVertex3d( (GLdouble)imgx, 0.0, 0.0 );
glTexCoord2d( 1.0, 1.0 );
glVertex3d( (GLdouble)imgx, (GLdouble)imgy, 0.0 );
glTexCoord2d( 0.0, 1.0 );
glVertex3d( 0.0, (GLdouble)imgy, 0.0 );
glEnd();
/* ダブルバッファリング */
glutSwapBuffers();
}
|
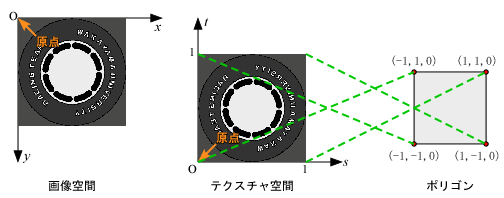
[ x, y, z ] |
[ s, t ] |
||
| [ 0.0, imgy, 0.0 ] | [ imgx, imgy, 0.0 ] | [ 0.0, 1.0 ] | [ 1.0, 1.0 ] |
| [ 0.0, 0.0, 0.0 ] | [ imgx, 0.0, 0.0 ] | [ 0.0, 0.0 ] | [ 1.0, 0.0 ] |
/*
** メイン関数
*/
int main( int argc, char *argv[] )
{
... 省略 ...
/* GLSLの初期設定 */
init_glsl(); /* コメント記号 // を外して有効にする */
... 省略 ...
/* GLSLの終了設定 */
fin_glsl(); /* コメント記号 // を外して有効にする */
... 省略 ...
}
/*
** GLSLの初期設定
*/
static void init_glsl( void )
{
... 省略 ...
/* フラグメントシェーダに値を渡す */
GLint smptexLoc = glGetUniformLocation( gl2Program, "smptex" ); // テクスチャサンプラ
glUniform1i( smptexLoc, 0 ); // テクスチャユニット GL_TEXTURE0 を利用
GLint imgxLoc = glGetUniformLocation( gl2Program, "imgx" ); // 画像の x 方向のピクセル数
glUniform1i( imgxLoc, imgx );
GLint imgyLoc = glGetUniformLocation( gl2Program, "imgy" ); // 画像の y 方向のピクセル数
glUniform1i( imgyLoc, imgy );
}
/*
** ウィンドウの描画
*/
static void display( void )
{
... 省略 ...
/* 4角形ポリゴンの描画 */
/* 4個の頂点にテクスチャ座標を割り当てる */
glBegin( GL_QUADS );
// glTexCoord2d( 0.0, 0.0 ); /* コメントアウトして無効にする */
glVertex3d( 0.0, 0.0, 0.0 );
// glTexCoord2d( 1.0, 0.0 ); /* コメントアウトして無効にする */
glVertex3d( (GLdouble)imgx, 0.0, 0.0 );
// glTexCoord2d( 1.0, 1.0 ); /* コメントアウトして無効にする */
glVertex3d( (GLdouble)imgx, (GLdouble)imgy, 0.0 );
// glTexCoord2d( 0.0, 1.0 ); /* コメントアウトして無効にする */
glVertex3d( 0.0, (GLdouble)imgy, 0.0 );
glEnd();
... 省略 ...
}
|
void main( void )
{
// 頂点のクリッピング座標
// gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// 上と下は同じ働きをする
gl_Position = ftransform();
}
|
// OpenGLアプリケーションの値を受け取る uniform 変数
uniform sampler2D smptex; // テクスチャサンプラ
uniform int imgx; // 画像の x 方向のピクセル数
uniform int imgy; // 画像の y 方向のピクセル数
void main ( void )
{
vec2 tex_st;
vec4 col;
// テクスチャ座標値の計算
tex_st.s = gl_FragCoord.x / float( imgx ); // 0.0 <= tex_st.s <= 1.0
tex_st.t = gl_FragCoord.y / float( imgy ); // 0.0 <= tex_st.t <= 1.0
// テクスチャの色のサンプリング
col = texture2D( smptex, tex_st );
// フラグメントの色
gl_FragColor.rgb = col.rgb;
}
|

/*
** ウィンドウの描画
*/
static void display( void )
{
... 省略 ...
/* 視野変換(ビューイング変換)の設定 */
gluLookAt( 0.0, 0.0, 1.0, /* 視点位置 */
0.0, 0.0, 0.0, /* 注目位置 */
0.0, 1.0, 0.0 ); /* 上向きベクトル */
/* モデリング変換 */
glTranslated( (GLdouble)imgx/3.0, (GLdouble)imgy/6.0, 0.0 );
glRotated( 30.0, 0.0, 0.0, 1.0 );
glScaled( 0.5, 0.5, 1.0 );
/* 4角形ポリゴンの描画 */
/* 4個の頂点にテクスチャ座標を割り当てる */
glBegin( GL_QUADS );
... 省略 ...
}
|
モデリング変換なし |
OpenGLアプリケーションのみを利用 |
シェーダを利用 |
|
|
|
// フラグメントシェーダに渡す値を格納するvarying変数
varying vec2 vert_xy; // 4角形ポリゴンのモデリング座標の x, y 値
void main( void )
{
// 頂点のクリッピング座標
// gl_Position = gl_ModelViewProjectionMatrix * gl_Vertex;
// 上と下は同じ働きをする
gl_Position = ftransform();
// 頂点のモデリング座標の x, y 値
vert_xy.xy = gl_Vertex.xy;
}
|
// OpenGLアプリケーションの値を受け取るuniform変数
uniform sampler2D smptex; // テクスチャサンプラ
uniform int imgx; // 画像のx方向のピクセル数
uniform int imgy; // 画像のy方向のピクセル数
// バーテックスシェーダから渡される値を格納するvarying変数
varying vec2 vert_xy; // 4角形ポリゴンのモデリング座標の x, y 値
void main ( void )
{
vec2 tex_st;
vec4 col;
// テクスチャ座標値の計算
// tex_st.s = gl_FragCoord.x / float( imgx ); // 0.0 <= tex_st.s <= 1.0
// tex_st.t = gl_FragCoord.y / float( imgy ); // 0.0 <= tex_st.t <= 1.0
tex_st.s = vert_xy.x / float( imgx ); // 0.0 <= tex_st.s <= 1.0
tex_st.t = vert_xy.y / float( imgy ); // 0.0 <= tex_st.t <= 1.0
// テクスチャの色のサンプリング
col = texture2D( smptex, tex_st );
// フラグメントの色
gl_FragColor.rgb = col.rgb;
}
|
モデリング変換なし |
OpenGLアプリケーションのみを利用 |
フラグメント座標値 gl_FragCoord を利用 |
モデリング座標値 gl_Vertex を利用 |
|
|
|
 |
/*
** メイン関数
*/
int main( int argc, char *argv[] )
{
/* 画像の読み込み */
if( getPPM( imgname, &imgx, &imgy, img ) != 0 ) {
fprintf( stderr, "error: main() -> getPPM() -> %s\n", imgname );
return( 1 );
}
/* 【実験】シェーダの利用による処理の高速化 (2ー1) */
int num = 10000; // 繰り返し回数
float avg, sum;
for( int y = 0; y < imgy; y++ ) {
for( int x = 0; x < imgx; x++ ) {
avg = ( ((float)img[imgx*y+x][0]/255.0)
+ ((float)img[imgx*y+x][1]/255.0)
+ ((float)img[imgx*y+x][2]/255.0) ) / 3.0;
sum = 0.0;
for( int n = 0; n < num; n++ ) {
sum += avg;
}
img[imgx*y+x][0] = img[imgx*y+x][1] = img[imgx*y+x][2]
= (unsigned char)( (sum/(float)num)*255.0 );
}
}
/* OpenGLの初期化 */
glutInitWindowSize( imgx, imgy );
... 省略 ...
/* GLSLの初期設定 */
// init_glsl();
... 省略 ...
/* GLSLの終了設定 */
// fin_glsl();
... 省略 ...
}
|
/*
** メイン関数
*/
int main( int argc, char *argv[] )
{
/* 画像の読み込み */
if( getPPM( imgname, &imgx, &imgy, img ) != 0 ) {
fprintf( stderr, "error: main() -> getPPM() -> %s\n", imgname );
return( 1 );
}
/* 【実験】シェーダの利用による処理の高速化 (2ー1) */
/* int num = 10000; // 繰り返し回数
float avg, sum;
for( int y = 0; y < imgy; y++ ) {
for( int x = 0; x < imgx; x++ ) {
avg = ( ((float)img[imgx*y+x][0]/255.0)
+ ((float)img[imgx*y+x][1]/255.0)
+ ((float)img[imgx*y+x][2]/255.0) ) / 3.0;
sum = 0.0;
for( int n = 0; n < num; n++ ) {
sum += avg;
}
img[imgx*y+x][0] = img[imgx*y+x][1] = img[imgx*y+x][2]
= (unsigned char)( (sum/(float)num)*255.0 );
}
} */
/* OpenGLの初期化 */
glutInitWindowSize( imgx, imgy );
... 省略 ...
/* GLSLの初期設定 */
init_glsl(); /* コメント記号 // を外して有効にする */
... 省略 ...
/* GLSLの終了設定 */
fin_glsl(); /* コメント記号 // を外して有効にする */
... 省略 ...
}
/*
** ウィンドウの描画
*/
static void display( void )
{
... 省略 ...
/* 4角形ポリゴンの描画 */
/* 4個の頂点にテクスチャ座標を割り当てる */
glBegin( GL_QUADS );
// glTexCoord2d( 0.0, 0.0 ); /* コメントアウトして無効にする */
glVertex3d( 0.0, 0.0, 0.0 );
// glTexCoord2d( 1.0, 0.0 ); /* コメントアウトして無効にする */
glVertex3d( (GLdouble)imgx, 0.0, 0.0 );
// glTexCoord2d( 1.0, 1.0 ); /* コメントアウトして無効にする */
glVertex3d( (GLdouble)imgx, (GLdouble)imgy, 0.0 );
// glTexCoord2d( 0.0, 1.0 ); /* コメントアウトして無効にする */
glVertex3d( 0.0, (GLdouble)imgy, 0.0 );
glEnd();
... 省略 ...
}
|
void main ( void )
{
... 省略 ...
// テクスチャの色のサンプリング
col = texture2D( smptex, tex_st );
/* 【実験】シェーダの利用による処理の高速化 (2ー2) */
int num = 10000; // 繰り返し回数
float avg, sum;
avg = ( col.r + col.g + col.b ) / 3.0;
sum = 0.0;
for( int n = 0; n < num; n++ ) {
sum += avg;
}
col.r = col.g = col.b = (sum/float(num));
// フラグメントの色
gl_FragColor.rgb = col.rgb;
}
|
OpenGLアプリケーションのみを利用 |
シェーダを利用 |
|
|
 |
 |
|
|
void main ( void )
{
int i, j;
vec4 col; // サンプリングしたテクスチャ色
vec3 avg = vec3( 0.0 ); // テクスチャ色の平均値
int m = 1; // 平滑化するピクセルの範囲
float w[9] // 重み w[(2*m+1)*(2*m+1)]
= float[9]( 0.1, 0.1, 0.1,
0.1, 0.2, 0.1,
0.1, 0.1, 0.1 );
... 省略 ...
for( j = -m; j <= m; j++ ) {
for( i = -m; i <= m; i++ ) {
... 省略 ...
// 変数 col にピクセル [ i, j ] について
// サンプリングしたテクスチャ色が入っているものとする.
avg.rgb += ( w[(2*m+1)*(m+j)+(m+i)] * col.rgb );
... 省略 ...
}
}
... 省略 ...
// フラグメントの色
gl_FragColor.rgb = avg.rgb;
}
|
|
|
|
|